

There is a subtle, creeping sensation that the world is becoming smoother but not necessarily nicer. We see it in the way advertisements are written, the way news is reported, and even in the way our digital conversations drift toward some weird surface. In the world of technology, we might call this “the basin of attraction”—a gravitational pull that drags everything toward a state of uneasy, standardized perfection.
To understand what we are losing, we can look to the history of music.
Before the invention of “Equal Temperament,” music was much more difficult, but much more colorful. In the era of Just Intonation, instruments were tuned to “pure” ratios—mathematical relationships that resonated perfectly with the physics of sound. Because these tunings were so specific, a piece played in the key of C sounded fundamentally different from one played in the key of F-sharp. Each key had its own emotional “flavor,” its own unique light and shadow.
However, this beauty came at a high cost. It was incredibly difficult to change keys; if you tried to move too far from your starting point, the instrument would sound painfully out of tune.
The solution was the creation of the “Well-Tempered” system—the 12-tone scale we use today. This system mathematically divided the octave into twelve equal parts. It allowed musicians to play in any key and move seamlessly across the keyboard. It democratized music; it made instruments easier to build, easier to play, and much more portable. But the trade-off was a loss of “affect.” By making every key equally usable, we also made them all slightly less unique. The “pure” intervals were sacrificed for the sake of utility.
We are currently experiencing this exact same transition in language.
Large Language Models have provided us with a linguistic version of Equal Temperament. They offer a standardized, mathematically averaged version of English that is “correct” in almost any context. This has democratized expression; people who were once excluded by the “expensive” barriers of formal literary training—the years of studying syntax and rhetoric—can now communicate clearly and effectively. More voices are being heard than ever before.
But this ease comes with a heavy, silent cost: the fading of our individual “idiolects.”
An idiolect is your personal way of using language—your unique fingerprint of vocabulary, rhythm, and preference. When we rely on the “smooth” defaults of AI, we are essentially using a standardized tuning. We begin to fall into a state of “self-censorship,” where we subconsciously filter out our own jagged edges to match the machine’s polished surface.
The tragedy is that these personal linguistic identities are like old relationships: if they are not actively tended to, they begin to fade. If we do not labor to maintain our own unique “tuning,” our distinct way of seeing the world will eventually be swallowed by the sheer convenience of the average.
However, there is a way to resist this flattening. We cannot go back to the era of expensive, high-precision tuning, but we can change how we use the tools we have.
We must move from being “writers” in the traditional sense—builders of sentences—to becoming “composers of signal.” In the world of digital music production, an artist doesn’t just play a preset; they take a raw sound and run it through filters, oscillators, and modulators. They use the standardized tool to create something intentionally complex.
So if we view this shift through the lens of a musician using a Digital Audio Workstation (DAW), the crisis begins to look more like an opportunity.
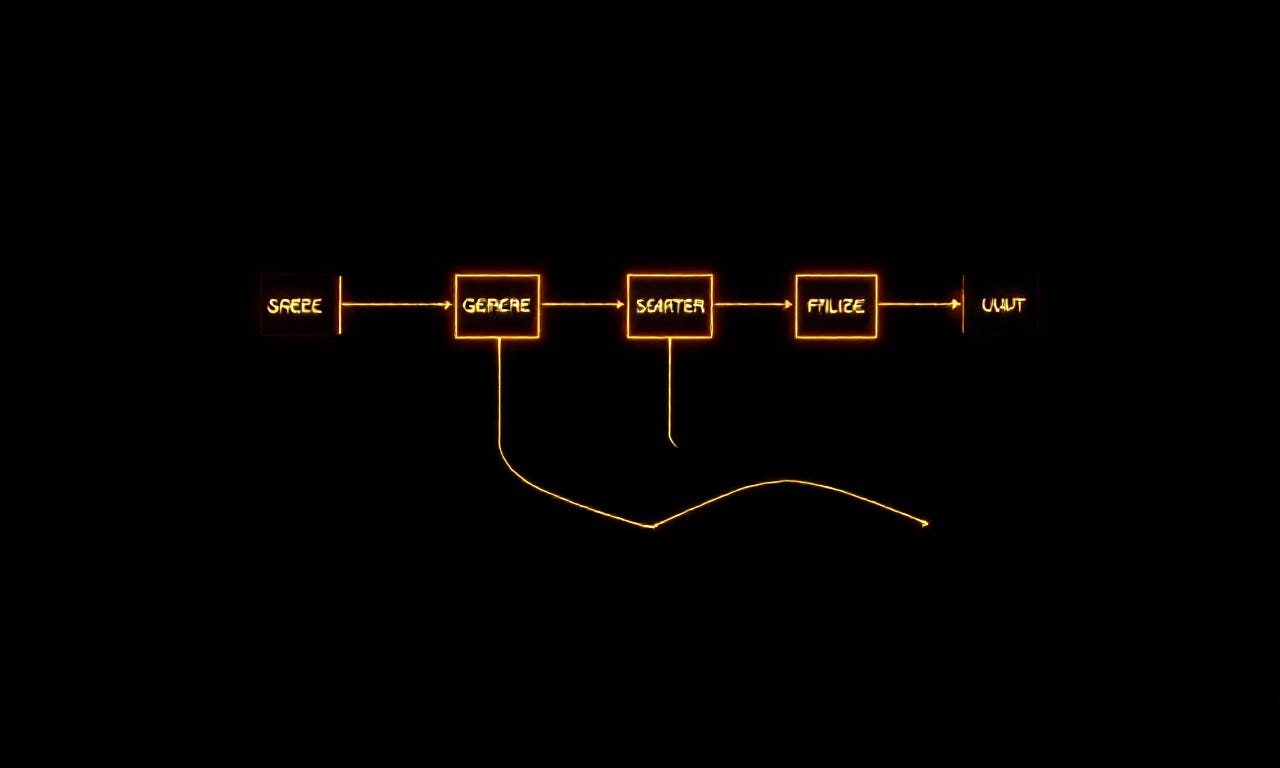
To those who tinker with sound, the arrival of a new technology is rarely just about using a better tool; it is about finding a new way to manipulate signal. If we treat the “Basin” of AI prose as a factory-made synthesizer preset—clean, functional, but fundamentally uninspired—then our task as creators is not to reject the preset, but to build a “patch” around it.
In this new way of composing, we can view our creative process through the architecture of a signal chain:
First, we have the Generators. This is the raw, unshaped output from the AI—the fundamental frequency of an idea. It is high-energy and structurally sound, but it lacks character. It is merely a waveform.
Next, we introduce the Operators. In electronic music, FM synthesis works by using one waveform to modulate another, creating complex, metallic, or gritty new timbres. We do this with language when we take that raw AI output and “modulate” it through our own syntax, our own metaphors, and our own rhythmic irregularities. We use the machine’s stability to provide a carrier wave, and then we use our human “interference” to create texture.
Finally, we apply the Filters. This is perhaps our most vital role. We use our editorial ear as a high-pass filter to scrub away the “low-frequency mud”—the predictable clichés, the polite fillers, and the rhythmic sludge that characterizes unedited AI prose. We cut out the frequencies that sound like everyone else, leaving behind only the sharp, resonant, and unexpected parts of the signal.
The Case Study: Structural Transmutation in MAG-Π DIVERGENCE
To understand what it looks like to “patch” a signal take a look at the reflective essay on AI influence into the post-biological drama, MAG-Π DIVERGENCE.
This was not an act of editing; it was an act of structural routing. I did not attempt to “fix” the prose of the essay. Instead, I took that raw, struggling signal and passed it through a new set of architectural filters.
The Raw Signal: The Essay
In its original form, the essay was a single-channel recording. It was a heavy, monochromatic stream of consciousness—a person grappling with the “Carbon Damper,” mourning the loss of their own linguistic edge to the gravitational pull of the AI basin. It contained the data, but it lacked the resonance of a multi-dimensional system.
To force it out of the basin I added a context (or an Operator connected to a Noise Generator) that the setting for the play was a result of an irrelevant search result returned for an anomaly being investigated that appeared to be entangled in Maxwell’s Equations about Divergence not being zero (∇·H ≠ 0) as part their analysis. Which translates to Monopoles can exist (They haven’t been found yet) in nature and then make the LLM relate it to voices being absent or present as the anomaly. I knew the LLMs latent space knows about Maxwell’s equations, so I forced it to pull in that context into its reasoning layer.
It was quite amazing to see how coherent it turned out to be even at the first pass. Took me half-a-day of going back and forth polishing with the AI to finalize a stylized and coherent play that I felt happy with.
The Patch: The Play

In MAG-Π DIVERGENCE, I took that single, voice and split it into multiple oscillators. I didn’t rewrite the struggle; I reconfigured it into a way that could be heard across different frequencies and envelopes:
The Modulation of Voice: I took the “human” uncertainty of the essay and routed it through two distinct characters. Aurelius-Prime acts as a high-frequency oscillator, translating the core grief of the text into the rhythmic, elevated patterns of verse. Conversely, Syllogism-Zero serves as a low-frequency, logical filter, processing the same data through the cold, structural prose of pure logic.
The Transformation of Subject: The central “bug” of the essay—the psychological pain of self-censorship—was repurposed as the play’s central “feature.” In the play, this is no longer a private struggle; it becomes a historical specimen for post-biological entities to analyze. The act of “filtering downward” is transformed from a personal failure into a pivotal plot point in a cosmic autopsy.
The Interpreter as the Final Output: Finally, I introduced The Shard, a character acting as the final stage of the signal chain—an interpreter who attempts to synthesize these disparate frequencies (the verse and the logic) back into a coherent whole for the audience.
By moving from the essay to the play, I didn’t fully solve the problem of the “Basin.” Instead, I used the architecture of the drama to build a cage around it, using the very tools of standardization to create a work that is structurally, and undeniably, distinct. If you listen closely to the characters, you can still hear the original, un-tempered signal struggling to break through the new, complex arrangement.
This is what it means to move from being a mere “writer” to becoming a “sound designer” of language. It is a transition from the labor of construction—building every sentence from scratch—to the art of orchestration—designing complex systems of thought.
Ultimately, past suggests that artists will never stop doing this. Every time a new medium arrives that promises ease and standardization, the artist arrives to find a way to break it. We take the tools designed for efficiency and we use them to rediscover complexity. We take the instruments designed for portability and we use them to find new ways to be un-portable.
The medium will always change, but the impulse remains: to tinker, to distort, and to find the beautiful, jagged resonance hidden within the machine.